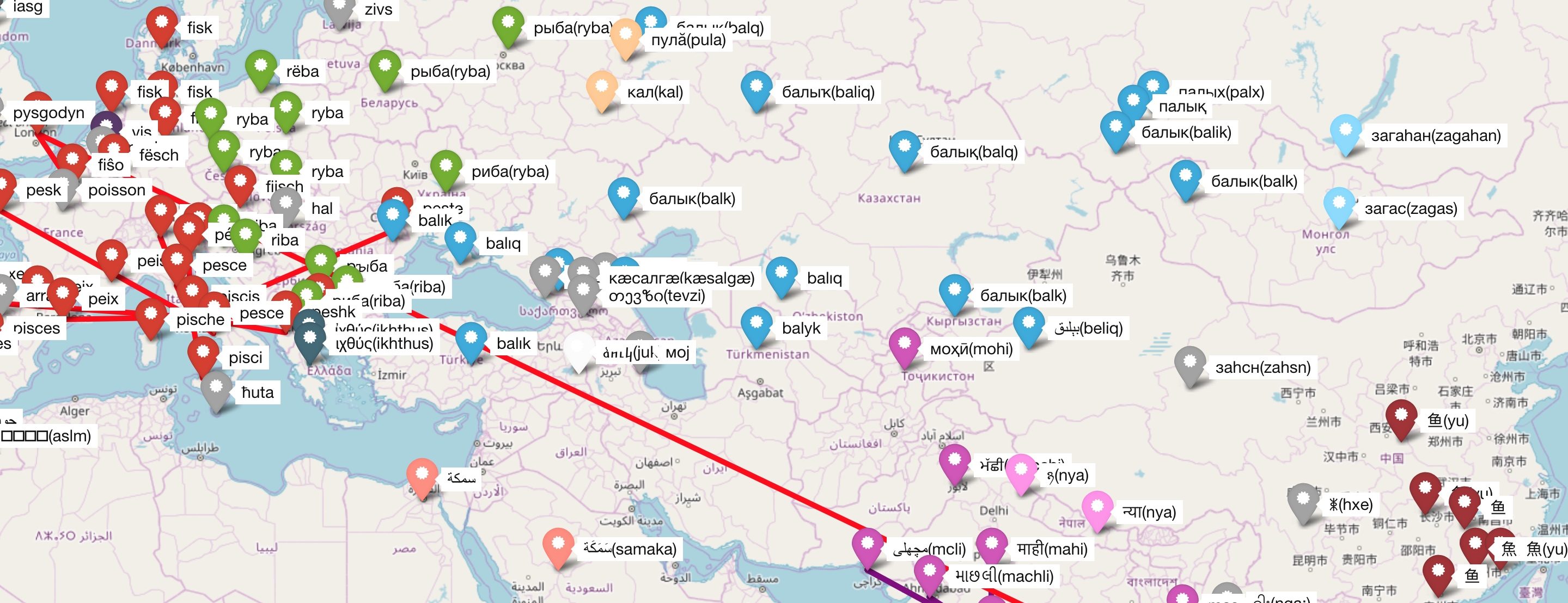
What is CogNet? It is a large-scale database of cognate pairs: it contains 8.1 million cognates in 338 languages, 38 writing systems, and 91285 concepts. It was automatically constructed from wordnets and dictionaries contained within the UKC resource, as described in our paper.
What are cognates? In short, cognates are words in different languages that share a common origin and the same meaning, such as the English letter and the French lettre. CogNet links its cognates to Princeton WordNet synsets, making the shared meanings explicit. Inside CogNet, two well-distinguished kinds of cognates are included:
- words that have the same meaning and are etymologically related according to gold-standard evidence (such as the Etymological WordNet or Wiktionary): such cognates, which constitute about 40% of CogNet, can be used for applications in historical linguistics;
- words that have the same meaning but we only have indirect evidence of their relatedness, such as orthographic or phonetic similarity. This corresponds to a more relaxed interpretation of cognacy that also includes, e.g., loanwords, and that is well suited for applications in computational linguistics such as machine translation or bilingual lexicon induction.
Why are cognates important? Cognates have been extensively studied in the fields of language typology and historical linguistics, as they are considered useful for researching the relatedness of languages. Cognates are also used in computational linguistics, e.g., for lexicon extension or to improve cross-lingual NLP tasks such as machine translation or bilingual lexicon induction.
How is CogNet licenced? Under CC-BY-SA-NC-4.0.
Where can I download CogNet? All versions of CogNet can be downloaded from the CogNet project GitHub page. See the table below for the contents of each version.
| Version | # Cognates | # Words | # Concepts | Precision | Kinds of evidence used |
|---|---|---|---|---|---|
| CogNet v2 | 8.14 M | 1.07 M | 91 k | 95.62% | etymological, phonetic, orthographic, geographic |
| CogNet v1 | 3.16 M | 570 k | 81 k | 93.94% | etymological, orthographic, geographic |
| CogNet v0 | 60 k | 90 k | 9 k | 100% | etymological only |
You can also download WikTra, the Wiktionary-based transliteration tool used for building CogNet.
How can I explore cognate data? Besides downloading the entire CogNet as a structured text file, you can also use the Linguarena website to display and browse (currently an older version of) cognate data interactively on a world map, as also shown in the figure above.
How is CogNet structured? Each row in the resource represents a cognate instance which is formed by the following individuals (columns are tab-separated):
| Column | Description |
|---|---|
| concept | A code used by Princeton WordNet 3.0 to represent a synset. |
| language 1 | the 3-letter iso code for the first language |
| word 1 | a word in the language 1 |
| language 2 | the 3-letter iso code for the second language |
| word 2 | a word in the language 2 |
| evidence | direct etymological or indirect algorithmic |
| transliteration 1 | a romanized word for the first word |
| tranlisteration 2 | a romanized word for the second word |
Example
| concept | lang1 | word1 | lang2 | word2 | evidence | transliteration1 | transliteration2 |
|---|---|---|---|---|---|---|---|
| n14996158 | glg | polipropileno | jpn | ポリプロピレン | ETY | NO_TRANSLIT | poripuropiren |
| n06566077 | nep | सफ्टवेर | kas | سافٹویٚیَر | ALG | saphtawera | saftoeyar |
Acknowledgements